
What makes RAG so effective? (How Attention Shapes Understanding in LLMs)

Since ChatGPT came out, I remember seeing several blogs and videos talking about this new technique called Retrieval-Augmented Generation. It worked exceedingly well in preventing hallucinations, and ensuring factually correct outputs. Since then, startups and libraries have been built just to help people optimise this process for their use cases.
What is Retrieval-Augmented Generation? RAG is a technique that uses an ability of LLMs known as In-Context Learning. That means that if we provide a context with some information that an LLM doesn’t know, LLMs are adept at learning new information from the context and answering the question accordingly.
For example, the user asks the LLM “What is the most popular language spoken in Chennai?” and the LLM incorrectly outputs “Hindi”.

In a RAG setup, the LLM might retrieve a Wikipedia article saying the following:
Once the LLM has retrieved this from the web, it prepends this to the question and feeds it back into the LLM to get an answer.

Providing the context leads to the correct answer, “Tamil”. One of the advantages of RAG is that it helps reduce hallucinations by ensuring the LLM first retrieves facts from the web and then at least gets the facts right.
But what’s going on internally?
Causal Tracing
I wrote an earlier blog that explains the process of Causal Tracing in detail. I’d strongly recommend going through that (specifically the section on “Causal Mediation Analysis”) before reading this blog.
Let’s consider the input: “What is the most popular language in Chennai?”
The idea behind causal tracing is figuring out which parts of the LLM are responsible for a particular behaviour. We saw over there that facts are stored in MLPs, and the MLP at the Last Subject Token (LST) significantly impacts the output. In this case, “Chennai” is the LST.
In the clean case, we don’t perform corruption and the LLM outputs “Hindi”.

If we corrupt the LLM, we get the wrong output, but after restoring only the MLP at the LST, we see that the LLM brings back the original output.
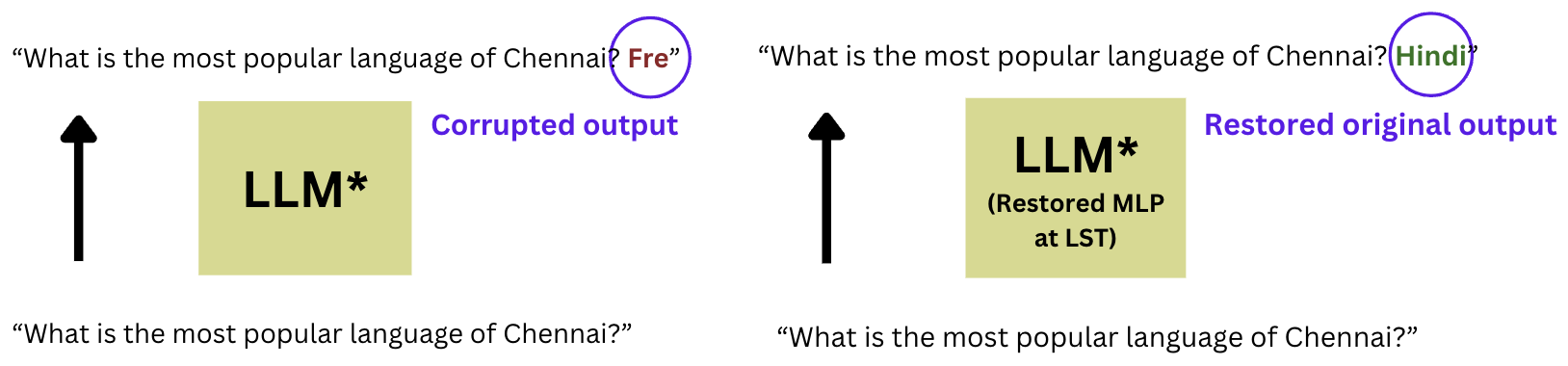
Restoring the MLP at the LST causes the probability of “Hindi” to rise, and we average this delta in probability over several statements, so we know it rises for multiple statements, not just one.
On the other hand, let’s consider the RAG setup, which accurately outputs “Tamil” in the clean case.

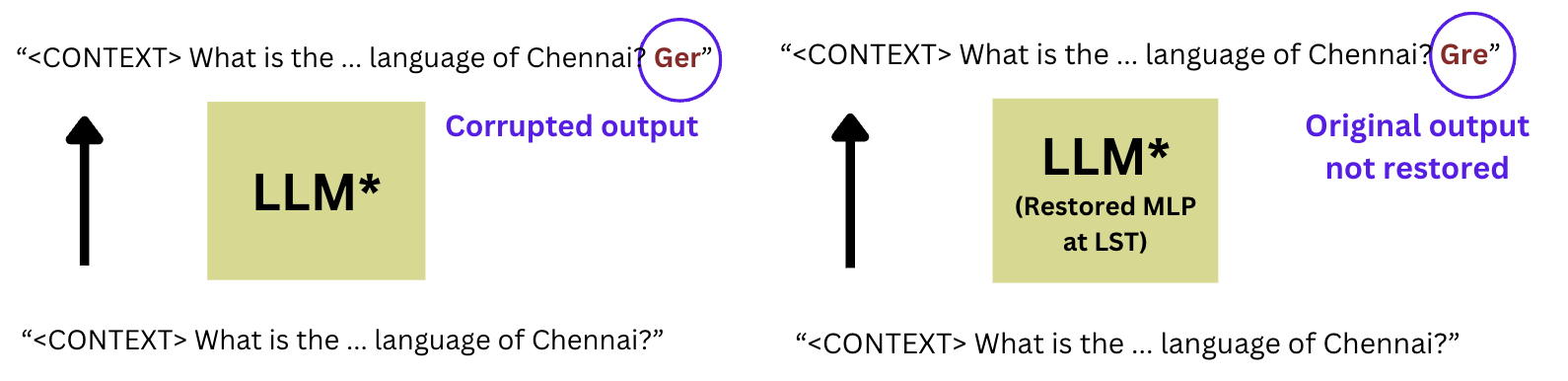
The hypothesis stated in our previous blog is that MLPs have something to do with factual recall. However, restoring the MLP hidden states at the LST no longer returns the original output (“Tamil”). It looks like MLP activations aren’t that important anymore.
That could mean the LLM is no longer utilising its parametric memory. This makes sense since we expect it to focus on the context rather than use its parametric memory.
So, if MLPs aren’t that important anymore, what is?
How Attention Works in LLMs
I’d recommend going over Jay Allamar’s blog post “The Illustrated Transformer” to better understand how attention works.
Attention is essential in LLMs because it allows LLMs to model the meaning of words based on other words in the input. For example, an “it” later in the sentence might refer to a noun that came before, and information needs to flow from the noun to the “it” to generate the next token. Thus, some dependencies must be facilitated across tokens to get the value of the attention block’s output. Here’s an awesome diagram from Jay Allamar’s blog post.
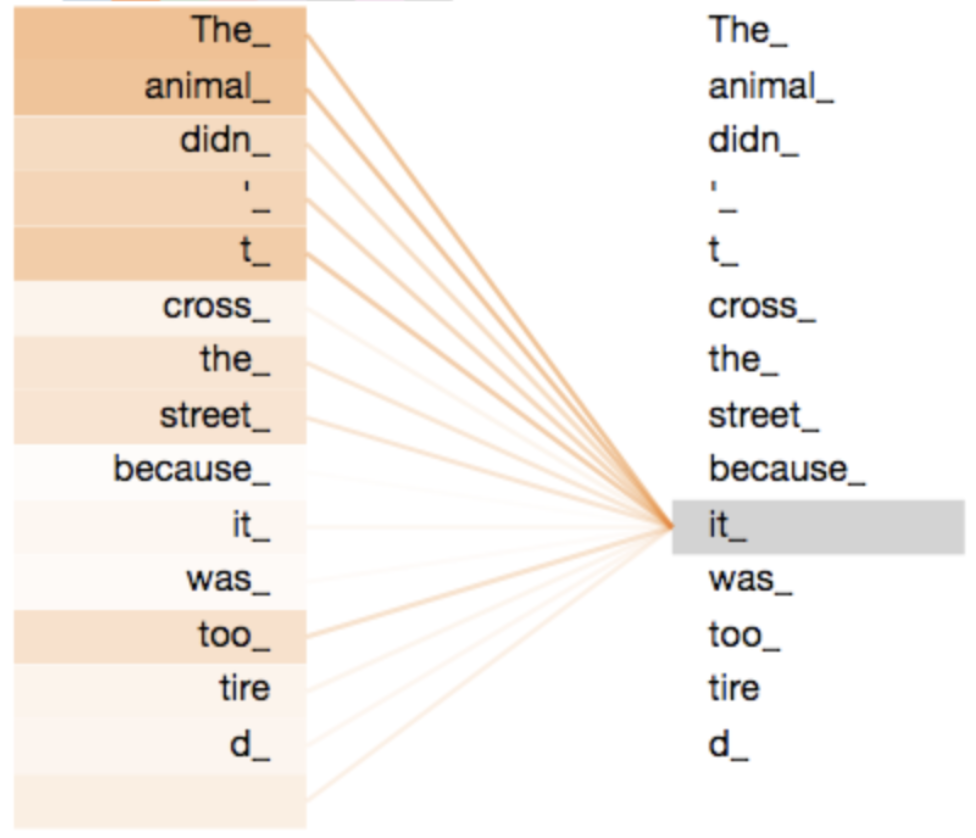
In this case, the “it” token is getting enriched by the “animal” token.
Attention Contributions
We can directly probe the attention values during inference. While generating the output “Tamil”, we can check which tokens our final token is enriched by during this generation.
The input to the LLM is a context plus a query. From now on, AT refers to the attribute token (the “Tamil” token within the context), and ST refers to the subject token (the “Chennai” token within the query).

They found out that the attention to the attribute token was much larger than the attention to the subject token (averaged across several examples). That shows that the LLM used the context to answer the question.
Attention Knockouts
We can also perform attention knockouts to confirm the importance of the attention values. This one is similar to causal analysis, where we knock out certain attention edges and see what effect that has on the final probability distribution and output.
To knock out attention edge weights, we set the attention values to 0. Here, we ensure that the last token is not enriched by the context’s attribute token (“Tamil”).
This significantly changes the LLM’s output, causing it not to output “Tamil”.
But let’s say we instead ensure the last token is not enriched by the query’s subject token (“Chennai”).
The LLM may still output “Tamil”, showing that this time, the attention wasn’t really that important.
Specifically, knocking out the attention edge to the subject token led to a 5% drop in the output probability (on average, across samples), while knocking out the attention edge to the attribute token led to a 20% drop in probability (on average).
Conclusions and Limitations
The main takeaway of the paper is that during a RAG setup, when a context is provided, the LLM relies much less on parametric memory and more on context to answer the question. Even though this sounds trivial, it also reinstates the fact that the memory of the LLM is somehow encoded into the MLPs and that these MLPs become a lot less critical in RAG setups. Knowing more about the mechanisms of these processes can help us further optimise the processes in various ways and help us think of ways to change the behaviour of an LLM without ever having to retrain it. For example, if lawyers couldn’t use an LLM that isn’t trustworthy enough to always output the correct answer as per the context, what if studying these attention weights and changing them in some way could force the LLM to stick to the context in a much more trustworthy fashion? Even if it’s not simple, we might get there soon.
Acknowledgements
The contents of this blog are from the paper From RAGs to rich parameters: Probing how language models utilise external knowledge over parametric information for factual queries by Hitesh Wadhwa et al. All diagrams were made using Canva.